
Dziś serwujemy tekst z nieco innego poletka – testowania oprogramowania, które przy okazji jest jedną ze specjalności na WWSIS na kierunku Informatyka. Studia w tej dziedzinie mogą okazać się przydatne do zrozumienia tekstu, ale nie są niezbędne, wystarczy znać pewne podstawy. Mamy nadzieję, że sprawi on Wam nieco radości i pokaże, zwłaszcza początkującym, że testy mogą być niezłą zabawą. A zatem – do dzieła!
PS Z uwagi na zainteresowania autora pożądana będzie otwartość czytelników na językoznawstwo. 🙂
*
Dla wielu osób darzących pewną tkliwością język cały jego tajemny urok tkwi w etymologii. To całkiem zrozumiałe. Nic bardziej romantycznego niż pomyśleć o astronaucie – gwiezdnym żeglarzu (od greckich słów astron/ἄστρον i nautes/ναύτης), nic zabawniejszego od wyobrażenia sobie pozornie pociesznego, lecz w rzeczywistości groźnego hipopotama, który z jakiegoś powodu zdawał się przypominać starożytnym Grekom… konia rzecznego (czego dowodzą niezbicie składające się na niego wyrazy hippos/ἵππος oraz potamos/ποταμός).
Chciałoby się zatem skorzystać z takiego ułatwienia i zapamiętać chociaż kilka takich rdzeni, żeby ułatwić sobie naukę. Istnieją oczywiście aplikacje oferujące taką możliwość – dziś na warsztat weźmiemy jedną z nich, Greek and Latin Roots Finder. Nie jest zbyt złożona, więc w rozsądnym czasie można przetestować każdą z jej funkcji: wyszukiwanie rdzeni wyrazów, poprawność danych zawartych w tabeli oraz testy (powtórkę z wiadomości). Prześledzimy działanie całego programu krok po kroku poprzez krótką eksplorację.
Zacznijmy od rzeczy zupełnie podstawowej – wpiszmy dowolne słowo, które nas interesuje, aby wyszukać jego rdzeń. Możemy wybrać na przykład łaciński wyraz dēfendere oznaczający obronę (od niego wzięły się np. angielskie defence albo polska defensywa). Powinna się wtedy pojawić cząstka fend – czysty rdzeń bez przedrostka i końcówki fleksyjnej. Naszym oczom ukazuje się jednak coś innego:
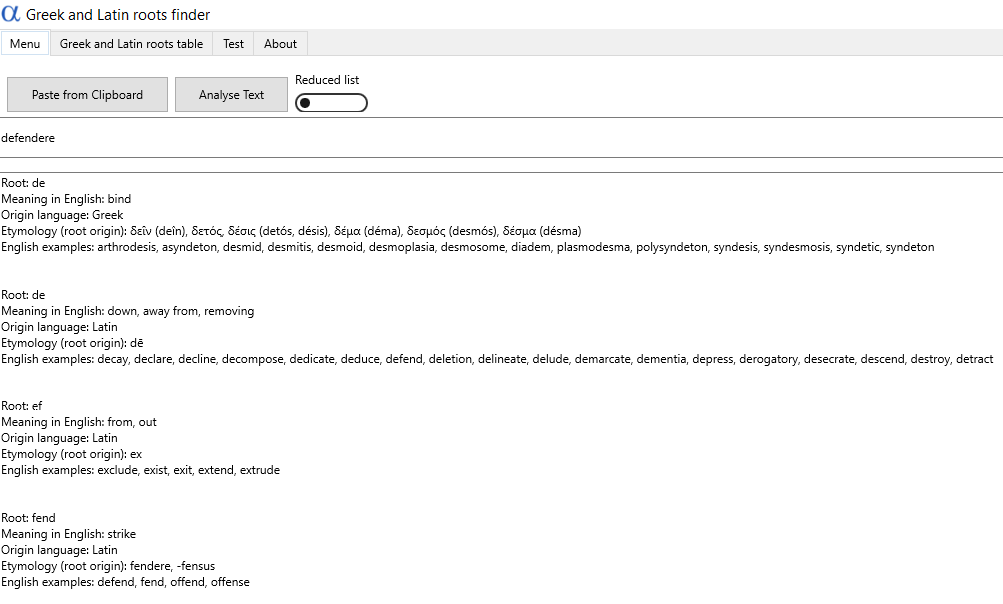
Okazuje się, że wyszukiwarka wyciąga ze słowa wszystkie znaczące zbitki liter, traktując każdy z nich jako potencjalny rdzeń. Pojedyncze słowo nie może mieć jednak czterech rdzeni, a jeden! To poważna wada programu – nie da się z niego korzystać efektywnie, skoro za każdym razem trzeba samemu wybrać odpowiedni rdzeń z całej, często długiej listy.
Mimo wszystko użytkownik może wciąż oczekiwać, że prędzej czy później dotrze do interesującej go etymologii. Sprawdźmy, czy tak jest w istocie, wyszukując kilka popularnych łacińskich słów, które znajdziemy już w pierwszych kilku(nastu) lekcjach zawartych w dowolnym podręczniku: pulcher, foedus, tristis, piger, lugeo, nox.
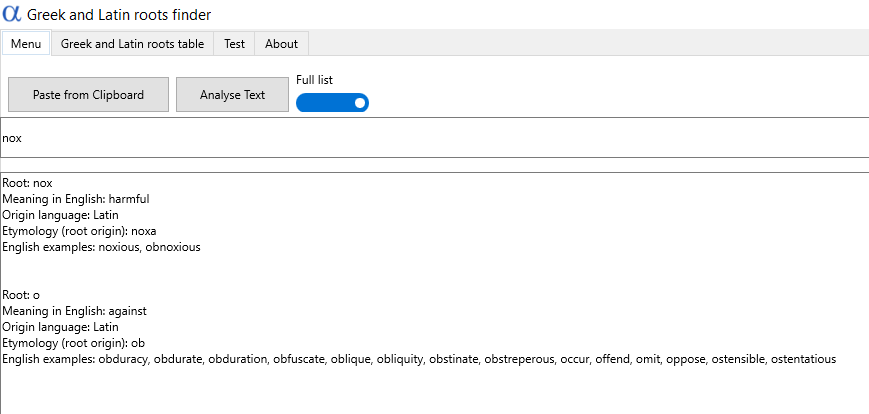
Niestety wyszukiwarka nie znalazła żadnego z podanych wyrazów – problem ten dotyczy zarówno listy niepełnej, jak i rozszerzonej (możemy wybierać je suwakiem). Ale czy naprawdę jest aż tak źle? Może da się znaleźć jakiś wytrych? Do tej pory sprawdzaliśmy aplikację, używając form najbardziej logicznych, zdroworozsądkowych – podstawowych, w mianowniku i liczbie pojedynczej. Co, gdyby nam się powiodło, wybierając inne? Oto skutki:
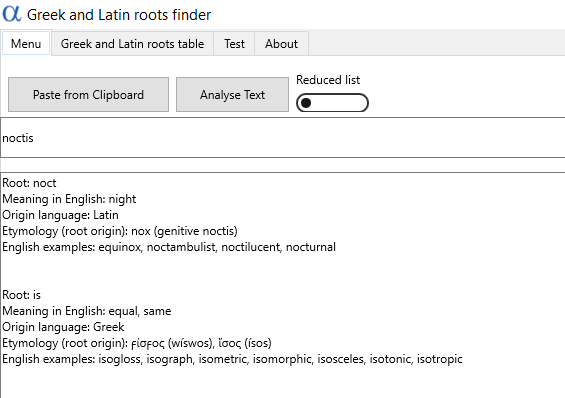
Wbrew wszelkim oczekiwaniom udało się! Podając dopełniacz od słowa nox, od razu znajdziemy właściwy rdzeń. Sztuczka ta działa jednak tylko na rzeczowniki mające różne tematy (nox i noctis – sami widzicie różnicę).
Co w takim razie z wyrazami nieregularnymi? Czy aplikacja poradzi sobie z nimi lepiej niż z tymi odmieniającymi się standardowo? Taką hipotezę, choć przedziwną, też trzeba zweryfikować. Sprawdźmy to na przykładzie czasownika fero, fere, tuli, latum – dość podchwytliwego, ponieważ ma różne rdzenie.


Tym razem, odwrotnie niż poprzednio, program poradził sobie tylko z oczywistym zadaniem. Udało się wyszukać rdzeń jedynie dla pierwszych dwóch form czasownika, dla pozostałych – nie.
Do tej pory zakładaliśmy, że wyszukiwarka będzie podawać wyłącznie prawdziwe rdzenie. Nawet jeśli wyświetli ich kilka i użytkownik będzie musiał jakiś wybrać, nie zostanie ewidentnie wprowadzony w błąd. Czy takie ryzyko, choćby najlżejsze, jest realne? Wypróbujmy najbardziej klasyczny przykład: canis (pies).
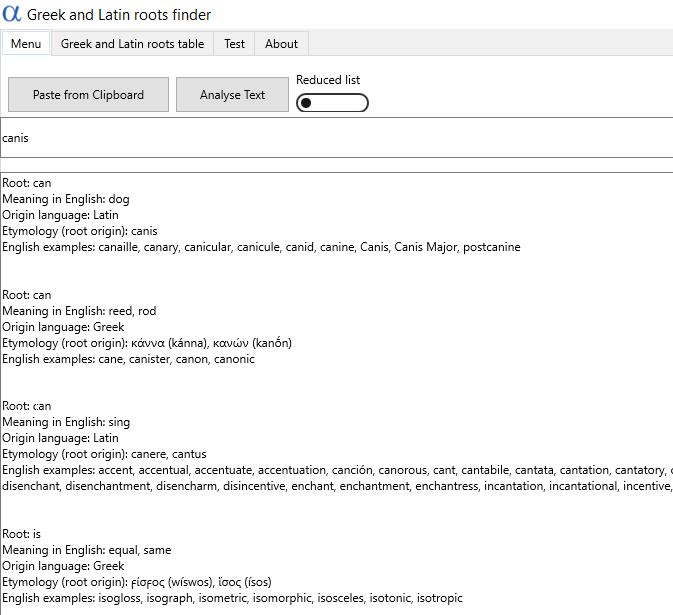
Jak widać, aplikacja sugeruje kilka możliwych powiązań – w tym fałszywą etymologię z długą historią. Warron, wybitny rzymski uczony, stwierdził niegdyś w swoim dziele De lingua latina, że wyraz canis musi pochodzić od canere (śpiewać), choć miał na myśli raczej wycie niż jakieś szczególne umiejętności wokalne. Użytkownik prawdopodobnie i tak poprzestanie na pierwszym wyniku wyszukiwania, więc ostatecznie nie zostanie wprowadzony w błąd, ale usterka wciąż usterką pozostaje.
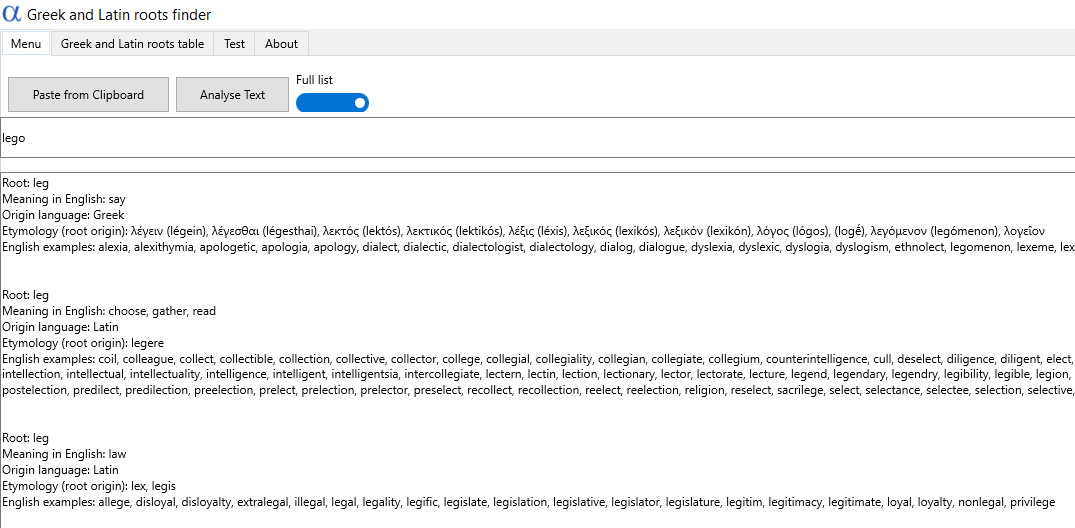
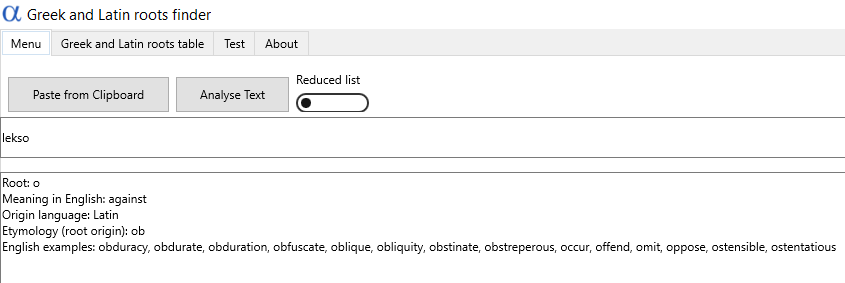
Dość łaciny. Pora na grekę! Jak można podejrzewać – ale sprawdzić i tak to trzeba – aplikacja nie radzi sobie z nią znacznie lepiej. Błędy są mniej więcej te same: nie wyszukuje wielu słów zapisanych w transkrypcji angielskiej (np. menin/μῆνιν od pierwszego słowa Iliady) albo nie radzi sobie z innymi formami niż podstawowe (znajdzie lego/λέγω, ale już nie lekso/λέξω).

Do przetestowania zostaje jeszcze przycisk „Paste form Clipboard”. Jest jasne, że zazwyczaj aplikacja zadziała tak samo jak podczas zwykłego pisania na klawiaturze. Sprawdźmy więc mniej oczywiste opcje: wklejenie słów z Wiktionary, strony niezwykle przydatnej dla każdego filologa, bo zawierającej masę przydatnych informacji o wyrazach. Witryna jest przy tym bardzo dokładna – słowa łacińskie podaje od razu z iloczasem, a greckie są zapisane w oryginalnym alfabecie.

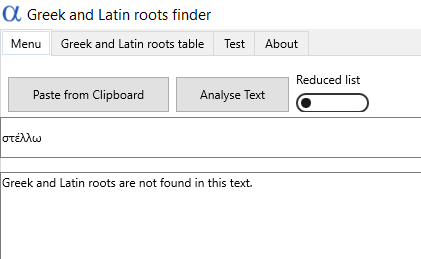
Oba słowa – ranarum i stello – zapisane w takiej właśnie jak w tym zdaniu formie wyszukiwarka spokojnie odnajdzie. Nie sprosta jednak wyrazowi z długą samogłoską zawartą w temacie ani zapisanemu po grecku. Funkcja wklejenia ma więc mocno ograniczoną przydatność.
Pora przejść wreszcie do tabeli z rdzeniami. Na ogół odznacza się dużą dokładnością, i ona ma jednak swoje mankamenty.



Pierwszy przykład może wywołać pewną konsternację. Wyszukiwarka nie obsługuje wyrazów z zaznaczonym iloczasem w temacie – jak amāre – ale tabela już je podaje. Gdyby przyszło nam do głowy wklejenie tego słowa do wyszukiwarki (co jednak nie ma wielkiego sensu, skoro tabela zapewnia identyczne informacje, można to jednak sobie wyobrazić), niczego byśmy nie znaleźli. Z pewnością jest to rzecz do naprawienia.
Drobną wadą jest też niekonsekwentny zapis iloczasu. W amāre go widać, ale w amatus już nie (powinno być amātus). Zdarzają się też postklasyczny zapis wyrazów na „i” przez jotę – tu zaznaczono tylko jeden przykład – albo bezzasadne użycie digammy, litery oznaczającej dźwięk v/w, umieszczonej tu przez pomyłkę tu w słowie helisso (nie welisso).
Na sam koniec – przetestujmy testy! To być może najbardziej enigmatyczna część aplikacji, działa bowiem kontrintuicyjnie. Po udzieleniu poprawnej odpowiedzi wyświetla się szczegółowy opis rdzenia, etymologii i przykładów, a przy złej odpowiedzi już nie. Powinno być raczej odwrotnie – jeśli czegoś nie wiedzieliśmy, zdecydowanie bardziej potrzebowalibyśmy informacji, które pozwoliłyby nam utrwalić materiał. Obecne rozwiązanie na pewno nie sprzyja nauce.
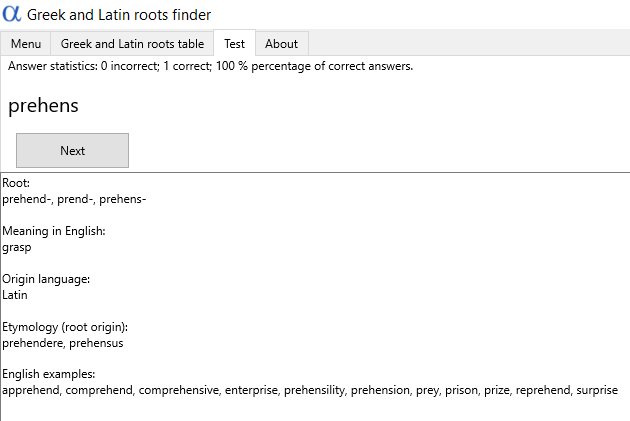
I jeszcze jeden drobiazg: testy językowe wydają się prowadzić donikąd, ponieważ się nie kończą. Nie ma wskazówki pozwalającej stwierdzić, czy jest jakaś określona, skończona liczba pytań, albo ile odpowiedzi trzeba mieć poprawnych, aby przejść dalej. Nie musi to być wcale defekt, ale warto byłoby rozważyć inną formę całej funkcji – mógłby to być na przykład jeden test z dziesięcioma pytaniami albo szereg coraz trudniejszych sprawdzianów.
Sam pomysł na program taki jak Greek and Latin Roots finder jest wyjątkowo cenny, ale na ten moment nie sprawdza się zbyt dobrze. Osoby zainteresowane etymologią muszą dalej polegać na innych źródłach – tradycyjnych słownikach albo choćby wspomnianej już Wiktionary. W obecnej wersji aplikacja nieszczególnie sprzyja uczeniu się: użytkownik musi zbyt wiele czasu poświęcać na szukanie właściwych rdzeni (których znać przecież wcale nie musi, od tego jest w końcu ten program), nie zawsze też będzie w stanie je znaleźć, a z rzadka zostanie wprowadzony w błąd. Zakładka z wklejaniem ma ograniczoną użyteczność, a testy – niewykorzystany potencjał. Do poprawy wciąż jest bardzo wiele.
Uff, to już prawie koniec! Dla osób o nieco mniejszym zacięciu filologicznym (nie każdy ma z nich studia magisterskie) – informatyka czy przyszłego testera też nie chcemy zaniedbywać – przygotowaliśmy bardziej techniczne ujęcie w postaci raportu z testu eksploracyjnego. Tu już bardziej przydadzą się studia informatyczne, ale bez nich też damy radę. 🙂
#STATUT Przetestuj aplikację Greek and Latin roots finder 2.5.0 pod kątem funkcji wyszukiwania rdzeni wyrazów, poprawności danych zawartych w tabeli oraz działania zakładki z testowaniem.
Podsumowanie: wykonano testy w wyżej wymienionym zakresie.
#OBSZAR Wyszukiwarka – NIE OK (defekty X1, X2, X3, X4, X5, X6, X7, X8, X9)
Tabela rdzeni – OK (defekty X10 i X11 są marginalne)
Testy – OK (defekt X12 jest niewielki)
OS |
System: Windows 10 Home 64-bit
Procesor: Intel(R) Core(TM) i3-5005U CPU @ 2.00GHz (4 CPUs)
Pamięć RAM: 4096 MB
Przeglądarka Chrome 75.0.3770.100
Menu |
– Menu
– Greek and Latin roots table
– Test
– About
Strategia |
testowanie funkcjonalne
Strategia | analiza funkcjonalna
#START 26.04.2020 r. 10:00
#TESTER Jakub Zbądzki
#PODZIAŁ ZADAŃ – brak
#CZAS TRWANIA Krótka (60 minut)
#PROJEKTOWANIE TESTÓW I WYKONANIE 38 minut
#BADANIE DEFEKTÓW I RAPORTOWANIE 20 minut
#PRZYGOTOWANIE SESJI 2 minuty
#PLIKI DANYCH
———————————————–
N/A
#NOTATKI Z TESTÓW
———————————————–
Udało się poddać testom wszystkie wskazane obszary – wyszukiwarkę, listę z rdzeniami oraz zakładkę z testami.
#STATUT kontra SZANSE
100/0
#DEFEKTY ———————————————–
DEFEKT X1
Po wpisaniu wybranego słowa wyszukiwarka nie podaje jego rdzenia, ale kolejne ciągi liter, z których najwyżej jeden jest faktycznym rdzeniem. Przykład: po wpisaniu czasownika defendere wyświetla się lista pięciu potencjalnych rdzeni (de, ef, fend, der, ere), ale tak naprawdę wyraz składa się tylko z trzech prostych elementów: przedrostka de, rdzenia fend i końcówki ere. Wyszukiwarka powinna wyświetlić jedynie fend.
DEFEKT X2
Wyszukiwarka nie znajduje wielu prawdziwych rdzeni nawet podstawowych łacińskich słów takich jak pulcher, foedus, tristis, piger, lugeo, gaudeo, nox.
DEFEKT X3
Wyszukiwarka nie znajduje czasem rdzenia rzeczownika w mianowniku, wyświetla go dopiero po użyciu innego przypadka, np. dopełniacza. Przykład: podaje prawdziwy rdzeń dla dopełniacza noctis, a dla mianownika nox już go nie wyświetla.
DEFEKT X4
Wyszukiwarka nie wyświetla rdzeni nieregularnych form czasowników łacińskich. Przykład: dla czasownika fero, fere, tuli, latum znajduje rdzenie tylko dla pierwszych dwóch wyrazów.
DEFEKT X5
Wyszukiwarka wskazuje fałszywe etymologie. Przykład: dla słowa canis podaje m.in. cano (błąd znany od starożytności).
DEFEKT X6
Wyszukiwarka nie znajduje wielu prawdziwych rdzeni nawet podstawowych greckich słów wpisywanych zgodnie z zasadami angielskiej transkrypcji. Przykłady: menin, lambano, skopeo.
DEFEKT X7
Wyszukiwarka niekiedy nie wyświetla rdzeni dla innych niż podstawowe form czasowników greckich w angielskiej transkrypcji. Przykład: znajduje rdzeń dla formy lego, ale już nie dla lekso.
DEFEKT X8
Wyszukiwarka nie podaje prawdziwych rdzeni dla wklejonych ze schowka słów łacińskich, jeśli w ich rdzeniu bądź temacie znajduje się znak długiej samogłoski. Przykład: znajduje rdzeń dla ranarum, ale już nie dla rānārum.
DEFEKT X9
Wyszukiwarka nie podaje rdzeni dla wklejonych ze schowka słów greckich, jeśli są zapisane w oryginalnym alfabecie. Dotyczy to także słów wpisanych w aplikacji do tabeli, jak στέλλω.
DEFEKT X10
W niektórych wyrazach łacińskich na liście rdzeni brakuje iloczasu. Przykład – amatus zamiast amātus.
DEFEKT X11
Drobne błędy w zapisie na liście rdzeni. Przykład: postklasyczne juvo zamiast iuvo, błędnie zamieszczona digamma w wyrazie helisso.
DEFEKT X12
Po udzieleniu poprawnej odpowiedzi w testach wyświetla się szczegółowy opis rdzenia, etymologii i przykładów, a przy złej odpowiedzi już nie, co nie sprzyja nauce.
… DEFEKT <niezaraportowany>
Testy językowe wydają się donikąd nie prowadzić. Po udzieleniu 36 odpowiedzi (29 dobrych, 7 złych), test wciąż trwa. Nie ma wskazówki pozwalającej stwierdzić, czy jest jakaś określona, skończona liczba pytań, albo ile odpowiedzi trzeba mieć poprawnych, aby przejść dalej. Rzecz wymaga dokładniejszego zbadania.
Chcesz dowiedzieć się więcej o testowaniu? Polecamy spróbować tego na własną rękę na portalach crowdtestingowych, a także zgłębić wiedzę techniczną na uczelni, niezależnie od tego, czy będą to studia I stopnia, czy studia II stopnia – Informatyka jest dziedziną, w której przyda się jeszcze wiele umysłów, także z doświadczeniem w najróżniejszych, nawet najbardziej nieoczekiwanych dziedzinach. 🙂